
Arithmetic mean vs Geometric mean
Posted by Kelvin on 24 Aug 2010 | Tagged as: programming
I've been brushing up on some basic statistics, and ran into this interesting bit of information.
We're all familiar with the average of a set of values, also known as the mean.
Arithmetic Mean
Turns out that there's more than one way to calculate the mean of a distribution. The method we probably associate with the average, is also known as the arithmetic mean.
The arithmetic mean is calculated by adding up all the numbers in a data set and dividing the result by the total number of data points.
Example: Arithmetic mean of 11, 13, 17 and 1,000 = (11 + 13 + 17 + 1,000) / 4 = 260.25
Geometric Mean
There is another way to calculate the mean, known as the geometric mean.
This is calculated by multiplying the numbers in the dataset, and taking the nth root of the result.
Example: Geometric mean of 11, 13, 17 and 1,000 = 4th root of (11 x 13 x 17 x 1,000) = 39.5
Geometric Mean and Logarithm
Another way to think of the geometric mean, is as the average of the logarithmic values of a data set, converted back to a base 10 number.
Lets work this out with the numbers 2 and 32.
So, the first way of calculating the geometric mean is by multiplication, then nth root:
sqrt(2 x 32) = sqrt(64) = 8
Remember, we take a square root because n=2, which is the 2nd root or square root.
Now, the second way of calculating the geometric mean is by expressing the numbers in term of a logarithm. In this case, we'll choose base-2.
2=21
32=25
21 x 25 = 26 (=64)
the square root of 26 is 23 (=8)
Another way of arriving at the same result is by taking the average of the exponents, i.e. (1+5)/2 = 3. Then re-expressing in terms of base 10, i.e. 23 = 8.
When to use which
If you look again at the first example given above,
Arithmetic mean of 11, 13, 17 and 1,000 = (11 + 13 + 17 + 1,000) / 4 = 260.25
Geometric mean of 11, 13, 17 and 1,000 = 4th root of (11 x 13 x 17 x 1,000) = 39.5
A geometric mean, unlike an arithmetic mean, tends to dampen the effect of very high or low values, which might bias the mean if a straight average (arithmetic mean) were calculated.
As stated on eHow.com:
Statisticians use arithmetic means to represent data with no significant outliers. This type of mean is good for representing average temperatures, because all the temperatures for January 22 in Chicago will be between -50 and 50 degrees F. A temperature of 10,000 degrees F is just not going to happen. Things like batting averages and average race car speeds are also represented well using arithmetic means.
Geometric means are used in cases where the differences among data points are logarithmic or vary by multiples of 10. Biologists use geometric means to describe the sizes of bacterial populations, which can be 20 organisms one day and 20,000 the next. Economists can use geometric means to describe income distributions. You and most of your neighbors might make around $65,000 per year, but what if the guy up on the hill makes $65 million per year? The arithmetic mean of the income in your neighborhood would be misleading here, so a geometric mean would be more suitable.
Geometric mean is often used to evaluate data covering several orders of magnitude. If your data covers a narrow range, or if the data is normally distributed around high values (i.e. skew to the left), geometric means may not be appropriate.
Geometric means is more appropriate than the arithmetic mean for describing proportional growth, both exponential growth (constant proportional growth) and varying growth; in business this is known as the compound annual growth rate (CAGR).
The geometric mean of growth over periods yields the equivalent constant growth rate that would yield the same final amount.
Do not use geometric mean on data that is already log transformed such as pH or decibels (dB).
Practical Applications
Many!
For example, according to this article:
Many wastewater dischargers, as well as regulators who monitor swimming beaches and shellfish areas, must test for and report fecal coliform bacteria concentrations. Often, the data must be summarized as a "geometric mean" (a type of average) of all the test results obtained during a reporting period. Typically, public health regulations identify a precise geometric mean concentration at which shellfish beds or swimming beaches must be closed.
A geometric mean, unlike an arithmetic mean, tends to dampen the effect of very high or low values, which might bias the mean if a straight average (arithmetic mean) were calculated. This is helpful when analyzing bacteria concentrations, because levels may vary anywhere from 10 to 10,000 fold over a given period. As explained below, geometric mean is really a log-transformation of data to enable meaningful statistical evaluations.
Average length of a URL (Part 2)
Posted by Kelvin on 16 Aug 2010 | Tagged as: programming
Here's a follow-up on my previous attempt at calculating the average length of a URL, which was naive and totally primitive.
In my previous attempt, I used the DMOZ urls and arrived at 4074300 unique URLs averaging 34 characters each.
The DMOZ dataset is inadequate for a number of reasons, most of all because DMOZ's URLs are skewed towards TLDs and towards domains that were popular in the earlier days of the internet where the practice of SEO-friendly url naming was not practiced.
This time round, I asked Ken, a friend who runs large crawls to fix me up with some URLs gleaned from some real-world crawls.
After some cleansing, I ended up with a dataset of 6,627,999 unique URLs from 78,764 unique domains.
Here's some R output:
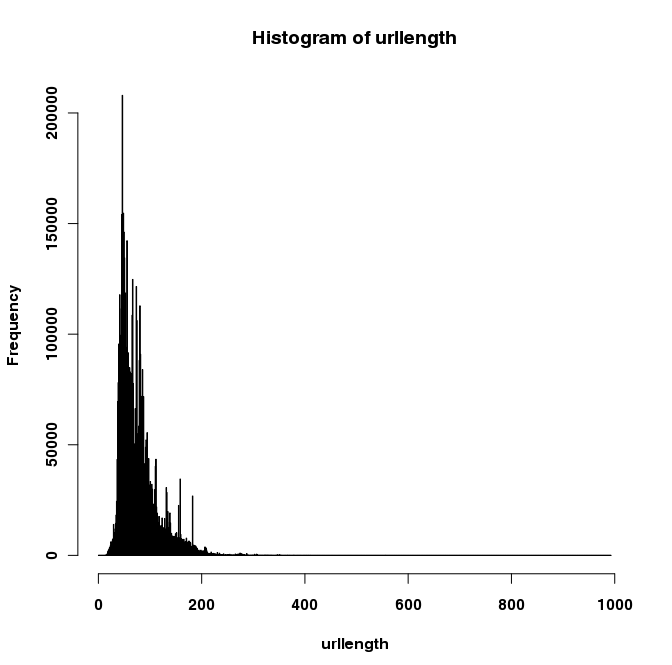
> summary(urls) Min. 1st Qu. Median Mean 3rd Qu. Max. 0.00 50.00 67.00 76.97 91.00 993.0 > sd (urls) # standard deviation [1] 37.4139 > quantile(urls, seq(0.95,1,0.005)) 95% 95.5% 96% 96.5% 97% 97.5% 98% 98.5% 99% 99.5% 100% 157 159 162 166 172 178 183 187 199 218 993
To summarize:
Mean: 76.97
Standard Deviation: 37.41
95th% confidence interval: 157
99.5th% confidence interval: 218
Here's a histogram for your viewing pleasure:
Dynamic facet population with Solr DataImportHandler
Posted by Kelvin on 02 Aug 2010 | Tagged as: Lucene / Solr / Elasticsearch / Nutch, programming
Here's what I'm trying to do:
Given this mysql table:
CREATE TABLE `tag` ( `id` INTEGER AUTO_INCREMENT NOT NULL PRIMARY KEY, `name` VARCHAR(100) NOT NULL UNIQUE, `category` VARCHAR(100) ); INSERT INTO tag (name,category) VALUES ('good','foo'); INSERT INTO tag (name,category) VALUES ('awe-inspiring','foo'); INSERT INTO tag (name,category) VALUES ('mediocre','bar'); INSERT INTO tag (name,category) VALUES ('terrible','car');
and this solr schema
<field name="tag-foo" type="string" indexed="true" stored="true" multiValued="true"/> <field name="tag-bar" type="string" indexed="true" stored="true" multiValued="true"/> <field name="tag-car" type="string" indexed="true" stored="true" multiValued="true"/>
to populate these tag fields via DataImportHandler.
The dumb (but straightforward) way to do it is to use sub-entities, but this is terribly expensive since you use one extra SQL query per category.
Solution
My general approach was to concatenate the rows into a single row, then use RegexTransformer and a custom dataimport Transformer to split out the values.
Here's how I did it:
My dataimporthandler xml:
<entity name="tag-facets" transformer="RegexTransformer,org.supermind.solr.TagFacetsTransformer" query="select group_concat(concat(t.category,'=',t.name) separator '#') as tagfacets from tag t,booktag bt where bt.id='${book.id}' and t.category is not null"> <field column="tagfacets" splitBy="#"/> </entity>
You'll see that a temporary field tagfacets is used. This will be deleted later on in TagFacetsTransformer.
package org.supermind.solr; import org.apache.solr.handler.dataimport.Context; import org.apache.solr.handler.dataimport.Transformer; import java.util.List; import java.util.Map; public class TagFacetsTransformer extends Transformer { public Object transformRow(Map<String, Object> row, Context context) { Object tf = row.get("tagfacets"); if (tf != null) { if (tf instanceof List) { List list = (List) tf; for (Object o : list) { String[] arr = ((String) o).split("="); if (arr.length == 2) row.put("tag-" + arr[0], arr[1]); } } else { String[] arr = ((String) tf).split("="); if (arr.length == 2) row.put("tag-" + arr[0], arr[1]); } row.remove("tagfacets"); } return row; } }
Here's the output via DIH's verbose output (with my own data):
<str name="tagfacets">lang=ruby#framework=ruby-on-rails</str> <str>---------------------------------------------</str> <lst name="transformer:RegexTransformer"> <str>---------------------------------------------</str> <arr name="tagfacets"> <str>lang=ruby</str> <str>framework=ruby-on-rails</str> </arr> <str>---------------------------------------------</str> <lst name="transformer:org.supermind.solr.TagFacetsTransformer"> <str>---------------------------------------------</str> <str name="tag-framework">ruby-on-rails</str> <str name="tag-lang">ruby</str> <str>---------------------------------------------</str> </lst> </lst> </lst>
You can see the step-by-step transformation of the input value.
Pretty nifty, eh?
Xpath select by node text value
Posted by Kelvin on 31 Jul 2010 | Tagged as: programming
//someparent/somenode[text() = 'foobar']
A kick-ass PHP mysql escaping function
Posted by Kelvin on 31 Jul 2010 | Tagged as: programming, PHP
Hate calling mysql_real_escape_string repeatedly in your code? Use these functions cobbled together from http://www.php.net/manual/en/function.mysql-real-escape-string.php
/** * USAGE: mysql_safe( string $query [, array $params ] ) * $query - SQL query WITHOUT any user-entered parameters. Replace parameters with "?" * e.g. $query = "SELECT date from history WHERE login = ?" * $params - array of parameters * * Example: * mysql_safe( "SELECT secret FROM db WHERE login = ?", array($login) ); # one parameter * mysql_safe( "SELECT secret FROM db WHERE login = ? AND password = ?", array($login, $password) ); # multiple parameters * That will result safe query to MySQL with escaped $login and $password. **/ function mysql_safe($query,$params=false) { if ($params) { foreach ($params as &$v) { $v = db_escape($v); } # Escaping parameters # str_replace - replacing ? -> %s. %s is ugly in raw sql query # vsprintf - replacing all %s to parameters $sql_query = vsprintf( str_replace("?","%s",$query), $params ); $sql_query = mysql_query($sql_query); # Perfoming escaped query } else { $sql_query = mysql_query($query); # If no params... } return ($sql_query); } /** * Automatically adds quotes (unless $quotes is false), but only for strings. Null values are converted to mysql keyword "null", booleans are converted to 1 or 0, and numbers are left alone. * Also can escape a single variable or recursively escape an array of unlimited depth. */ function db_escape($values, $quotes = true) { if (is_array($values)) { foreach ($values as $key => $value) { $values[$key] = db_escape($value, $quotes); } } else if ($values === null) { $values = 'NULL'; } else if (is_bool($values)) { $values = $values ? 1 : 0; } else if (!is_numeric($values)) { $values = mysql_real_escape_string($values); if ($quotes) { $values = '"' . $values . '"'; } } return $values; }
Usage
As a drop-in replacement for mysql_query when no placeholders (?) are used.
$result = mysql_safe("select 1 from table");
Use placeholders like so.
$result = mysql_safe("select ? from table where foo=?", array(1, "bar"));
The original mysql_safe function didn't escape numerics properly. The db_escape function does that nicely.
Hacking Django to set ENGINE=InnoDB for MySQL
Posted by Kelvin on 27 Jul 2010 | Tagged as: programming
In order to get Django to output innodb tables in MySQL, you either need to
1. output ALL tables as innodb or
2. selectively issue alter table commands
The first is sub-optimal (MyISAM is faster for query-dominant tables) and the second is a pain and hack-ish.
Here's a simple patch to Django 1.1 to allow you to specify table creation parameters via the Meta object, like so:
class test(models.Model): price = models.IntegerField() class Meta: db_table_creation_suffix = "ENGINE=InnoDB"
Its easy, with only 2 files to patch. Here are the steps.
1. Hunt down the django installation directory. On debian, using the python egg installation method, django is located /usr/lib/python2.5/site-packages/Django-1.1-py2.5.egg/django
2. Open db/models/options.py in a text editor. We'll be adding the "db_table_creation_suffix" field to the Meta object.
3. Near the top of the file, you'll see DEFAULT_NAMES = ('verbose_name', …)
Change this to look like this:
DEFAULT_NAMES = ('verbose_name', 'db_table', 'ordering', 'unique_together', 'permissions', 'get_latest_by', 'order_with_respect_to', 'app_label', 'db_tablespace', 'abstract', 'managed', 'proxy', 'db_table_creation_suffix')
The addition is
'db_table_creation_suffix'4. Now scroll a couple lines down and you'll see this:
self.duplicate_targets = {} # To handle various inheritance situations, we need to track where # managers came from (concrete or abstract base classes). self.abstract_managers = [] self.concrete_managers = []
Change this to look like this:
self.duplicate_targets = {} self.db_table_creation_suffix = None # To handle various inheritance situations, we need to track where # managers came from (concrete or abstract base classes). self.abstract_managers = [] self.concrete_managers = []
5. Open db/backends/creation.py in a text editor. We'll be performing the actual appending of the db_table_creation_suffix parameter.
6. Search for
full_statement.append(')')
7. BELOW this line, add this:
if opts.db_table_creation_suffix: full_statement.append(opts.db_table_creation_suffix)
That block of code should now look like this:
for i, line in enumerate(table_output): # Combine and add commas. full_statement.append(' %s%s' % (line, i < len(table_output)-1 and ',' or '')) full_statement.append(')') if opts.db_table_creation_suffix: full_statement.append(opts.db_table_creation_suffix) if opts.db_tablespace: full_statement.append(self.connection.ops.tablespace_sql(opts.db_tablespace))
8. Save and you're done!
The SQL now generated looks like this:
CREATE TABLE `test` ( `id` INTEGER AUTO_INCREMENT NOT NULL PRIMARY KEY, `price` INTEGER NOT NULL DEFAULT 0 ) ENGINE=InnoDB ;
SIGSEGV from memcpy+0x1c
Posted by Kelvin on 01 Jul 2010 | Tagged as: programming
JVM errors are mysterious and often difficult to reproduce, much less fix.
I've been getting some SIGSEGV from memcpy+0x1c JVM errors recently in long-running crawl processes, and in attempting to hunt down their cause, stumbled upon this: http://bugs.sun.com/bugdatabase/view_bug.do?bug_id=6366468
The interesting bit is here, from Thragor:
It seems I have found a way to reproduce this bug. It based on the assumption of dave_blake that it has something to do with a JAR being updated while being used.
I have two Hudson Jobs which may run in parallel. Let's call one the "producer" as it produces a JAR and the other one the "consumer" which depends on this JAR for a Maven Plugin to be called in generate-sources.
The producer provides a JAR which contains a file some.properties. The consumer uses a Maven Mojo which accesses this JAR through its classloader:
getClass().getClassLoader().getResources("META-INF/some.properties");
Now if you continuously build the producer project while the consumer project is build you will most likely get the failure as reported here.
I hope this is one additional indicator for how to reproduce this thing and perhaps finally find a solution for it.
My errors happened within Hudson too, but I'm fairly certain its not because of Hudson, but because, as Thragor suggests, the jars had been updated whilst being used.
Looking back, I do indeed see a correlation between my updating the jars and the JVM errors. It just hadn't occurred to me to put 2 and 2 together.
TokyoCabinet PHP Extension
Posted by Kelvin on 29 Jun 2010 | Tagged as: programming, PHP
I guess no one really interfaces directly with TokyoCabinet from PHP. For most cases, TokyoTyrant is probably more appropriate.
If you do need to though, check out http://code.google.com/p/1bacode/source/browse/trunk/front-end/extension/?r=12#extension/tokyocabinet.
Works great, and was surprisingly hard to find.
How to compile a PHP extension
Posted by Kelvin on 29 Jun 2010 | Tagged as: programming, PHP
Short answer
sudo apt-get install php5-dev
cd /path/to/extension
The extension directory must have a minimum of
1. config.m4
2. php_sample.h
3. sample.c
phpize
./configure make sudo make install
Now add the dynamic extension to your php.ini files in /etc/php5.
;;;;;;;;;;;;;;;;;;;;;; ; Dynamic Extensions ; ;;;;;;;;;;;;;;;;;;;;;; ; ; If you wish to have an extension loaded automatically, use the following ; syntax: ; ; extension=modulename.extension ; ; For example, on Windows: ; ; extension=msql.dll ; ; … or under UNIX: ; ; extension=msql.so ; ; Note that it should be the name of the module only; no directory information ; needs to go here. Specify the location of the extension with the ; extension_dir directive above. ; Example lines: extension=sample.so
Long answer
http://mattiasgeniar.be/2008/09/14/how-to-compile-and-install-php-extensions-from-source/
BuddyPress Activity Stream as Home Page results in Page Not Found
Posted by Kelvin on 23 Jun 2010 | Tagged as: programming
This is most likely the result of a deliberate or (in my case) accidental upgrade to WordPress 3.0, with which BuddyPress 1.2.4 is NOT compatible with.
The straightforward answer: downgrade WordPress 3.0 back to 2.9.
1. SSH into the server
2. Download WordPress 2.9
3. Go to the installation directory where WordPress 3.0 is installed.
4. Back everything up
5. rm wp*
6. rm -fr wp-include wp-admin
7. cp -fr wordpress2.9/wp* wordpress2.9/wp-include wordpress2.9/wp-admin .
That should do the trick.