Average length of a URL (Part 2)
Posted by Kelvin on 16 Aug 2010 at 02:49 pm | Tagged as: programming
Here's a follow-up on my previous attempt at calculating the average length of a URL, which was naive and totally primitive.
In my previous attempt, I used the DMOZ urls and arrived at 4074300 unique URLs averaging 34 characters each.
The DMOZ dataset is inadequate for a number of reasons, most of all because DMOZ's URLs are skewed towards TLDs and towards domains that were popular in the earlier days of the internet where the practice of SEO-friendly url naming was not practiced.
This time round, I asked Ken, a friend who runs large crawls to fix me up with some URLs gleaned from some real-world crawls.
After some cleansing, I ended up with a dataset of 6,627,999 unique URLs from 78,764 unique domains.
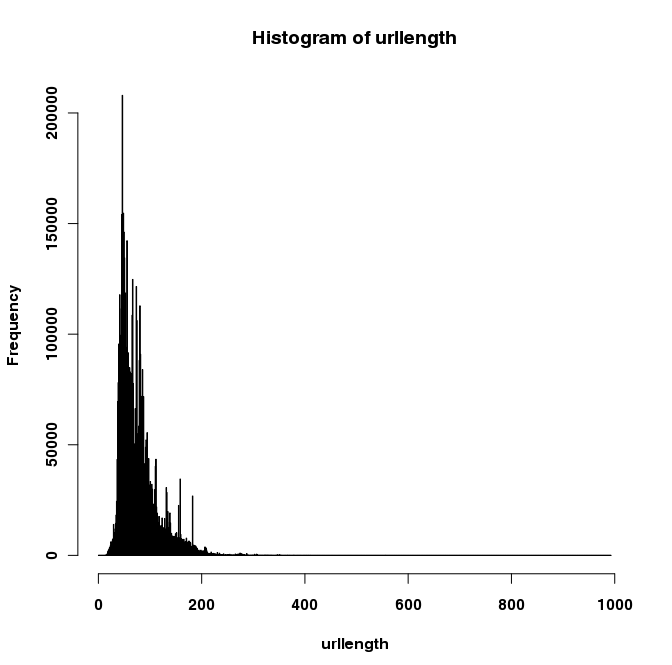
Here's some R output:
> summary(urls) Min. 1st Qu. Median Mean 3rd Qu. Max. 0.00 50.00 67.00 76.97 91.00 993.0 > sd (urls) # standard deviation [1] 37.4139 > quantile(urls, seq(0.95,1,0.005)) 95% 95.5% 96% 96.5% 97% 97.5% 98% 98.5% 99% 99.5% 100% 157 159 162 166 172 178 183 187 199 218 993
To summarize:
Mean: 76.97
Standard Deviation: 37.41
95th% confidence interval: 157
99.5th% confidence interval: 218
Here's a histogram for your viewing pleasure: